

概要
 THOR (THesaurus Oriented Retrieval)
THOR (THesaurus Oriented Retrieval)
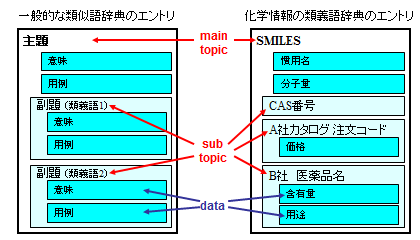
THORデータベースは、分子構造や物性値・注文番号などの情報を、類義語辞典のように階層状に分類し整理したものです。
- 情報の分類
-
- main topicタグ
「主題」に相当します。エントリ内の項目は、すべてmain topicに関係する内容になります。
例: 上の図では、化合物を表すSMILESがmain topicになります。 - sub topicタグ
「副題」に相当します。main topicと異なる表記がある場合に、sub topicで表現できます。
例: 上の図では、CAS番号や試薬会社の注文コード、main topicの化合物を含有する医薬品の名前などがsub topicになります。 - dataタグ
「意味」や「用例」に相当します。main/sub topicの内容が記述されます。
例: 上の図では、
1) 慣用名や分子量などの物性は、化合物自体に関係するので、main topicに直接属するdataになります。
2) 試薬の価格などは“注文コード”sub topicに属するdataになります。
3) 医薬品の用法や、化合物の含有量などは“医薬品名”sub topicに属するdataになります。
- main topicタグ
topicごとにdataを分類することで、THORデータベースは大量の情報を見通しよく保存し、管理することができます。
TDT (THOR DATA Tree)
TDTは、Daylight独自のデータベース形式です。THORシステムは、「化学情報の類義語辞典」をTDT形式で実現します。
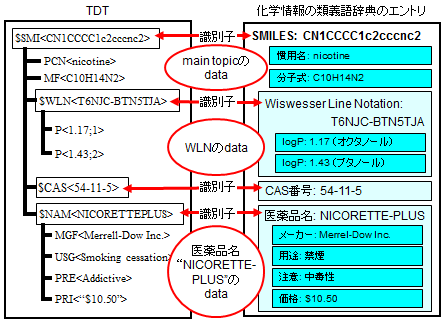
- XMLライクなツリー構造
-
- main topicを根に、sub topicを節に、dataを葉にしたツリー構造を持ちます。
- 根-節-葉の親子関係を規定するのは、記述の順序だけです。タグの入れ子関係などの複雑な記述は不要です。
- 識別子
-
- THORシステムは、識別子を使ってエントリを参照します。
- 識別子には、main topicとsub topicsが使われます。
- 「重複がなく、一意に決まるもの」「ユーザーが扱いやすい文字列や番号」が識別子に向いています。
- 柔軟なデータ格納
-
- バイナリ形式を含めた任意の形式のデータを格納できます。
- 関連する情報を同じ項目にまとめて格納できます。
例:logPの項目に「logP値」「溶媒」をまとめて保存します。 - 同じ項目を、共通の項目名で複数作ることができます。
例:異なる溶媒のlogP値を、同じ項目名“logP”で別々に保存します。 - エントリごとに保存するデータ項目が異なっていても、余分な保存領域は発生しません。
- データ計算・解析プログラム群
-
- TDTに対してデータを計算・解析し付加するプログラム群があらかじめ用意されています。
- SMILESからフィンガープリント、ClogP・CMR、各種分子記述子などを導出して付加できます。
- SMILESから互変異性体を網羅的に導出して付加できます。
