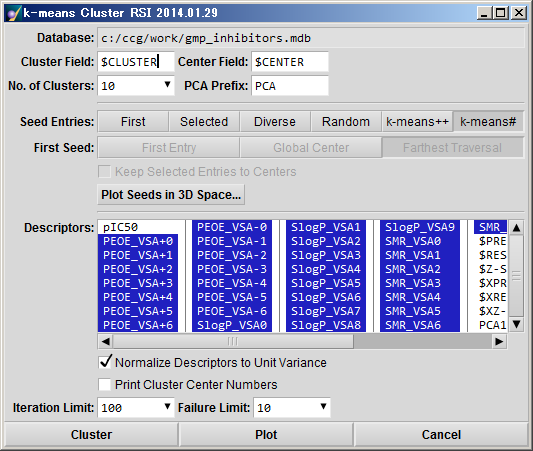
| Cluster Field: | クラスタ番号を書き出すフィールド名を設定します。 計算結果として同じ番号を持つエントリが同じクラスタであることを意味します。 |
| Center Field: | クラスタ中心を書き出すフィールド名を指定します。クラスタ中心となったエントリには1が入り、それ以外には0が入ります。 |
| No. of Clusters: | クラスタの数を指定します。 |
| PCA Prefix: | プロット用の主成分のフィールド名3つの語頭語を指定します。 |
| Seed Entries: | K-Meansアルゴリズムにおける初めの中心点の選択方法です。
|
| First Seed: | Diverseオプション用の最初の起点化合物の選択方法です。
|
| □ Keep selected entries to center: | Seed Entries が First, Selected, Diverse あるいは Random の場合、このオプションをオン (■)にすると、データベース中で選択してある化合物群を k 個の起点化合物群に含める |
| Plot Seeds in 3D Space: | のボタンをクリックすると、起点化合物群を MOE ウィンドウ内で三次元の PCA 空間内で表示する。化合物は小球で、クラスター中心は球で表示され、クラスター毎に色分けされる。 |
| ■ Normalize Descriptors to Unit Variance: | このオプションをオンにすると、各分子記述子の値を標準偏差で規格化する |
| □Print Cluster Center Numbers: | このオプションをオンにすると、SVL Commands ウィンドウのログにクラスター中心のエントリー番号が出力されます。(Centers: XXX…) |
| Iteration Limit: | この回数でクラスター中心の割り当ての計算が収束しなければ計算を終了する。 |
| Failure Limit: | 連続してこの回数、Costの減少(最小値の更新)がなければ計算を終了する。 |
改訂履歴:
2006/07/03
・プログラム名をkmean.svlからkmeans.svlに変更しました。
・起動コマンドをKMean[]からKMeans[]に変更しました。
・データベースの読み込み速度が早くなりました。
2006/12/01
・Keep selected entries to centerオプションを加えました。
2010/12/24
・各種起点化合物群の選択方法(Seed Entries)を加えました。
k-means++: D. Arthur, and S. Vassilvitskii, k-means++: the Advantages of Careful Seeding, http://www.stanford.edu/~darthur/kMeansPlusPlus.pdf.
k-means#: N. Ailon, R. Jaiswal, and C. Monteleoni, Streaming k-means approximation, http://books.nips.cc/papers/files/nips22/NIPS2009_1085.pdf.
SVLソースコードはこちら
Copyright(C) 2021 MOLSIS Inc. All Rights Reserved.
(株)モルシス